|
「家庭用パソコン」と「Excel」で「大型データ」を扱う!

|
和田 尚之 著
2022年 7月25日発売
A5判
168ページ
定価 ¥2,640(本体 ¥2,400)
|
|
ISBN978-4-7775-2206-4 C3004 ¥2400E
|
 |
「大きなデータ」を「小さなデータの集まり」にして考える「自己組織化」というアプローチを使うことで、かなりの「大型のデータ」への対応ができるようになります。
Excelを使って、大型データを自己組織化するための手順を解説。
|
|
| ■ 主な内容 ■ |
■「機械学習・AI」のイメージ
・大型データを「機械学習・AI」で解くために
・「機械学習・AI」の全体的なイメージ
・さらに「次のステップ」を目指したい方へ
■データを「場」として捉える
・「場」とは
・具体的な数理学での「場」(field)
■「自己組織化」の基礎
・あいまいな状態を測る道具「隠れた次元」
・「群の破れ」という考え方
・「ハウスドルフ次元外測度」という考え方
・ナスカの地上絵をAIで解く
■時間に依存しない「場」のモデルケース
・街道のモデルケース「佇まい」を考える
・峠のモデルケース「あやうい」を考える
■時間に依存する「場の風景」のモデルケース
・商いの風景(商店の売り上げのモデルケース)
・路の風景(人の脳波を使った景観のモデルケース)「ふうけい」を考える
・「ハイリスク&ハイリターン」を四分位数で解く
■「自己組織化」のための「多変数の合成理論」
・「時間依存」と「時間非依存」
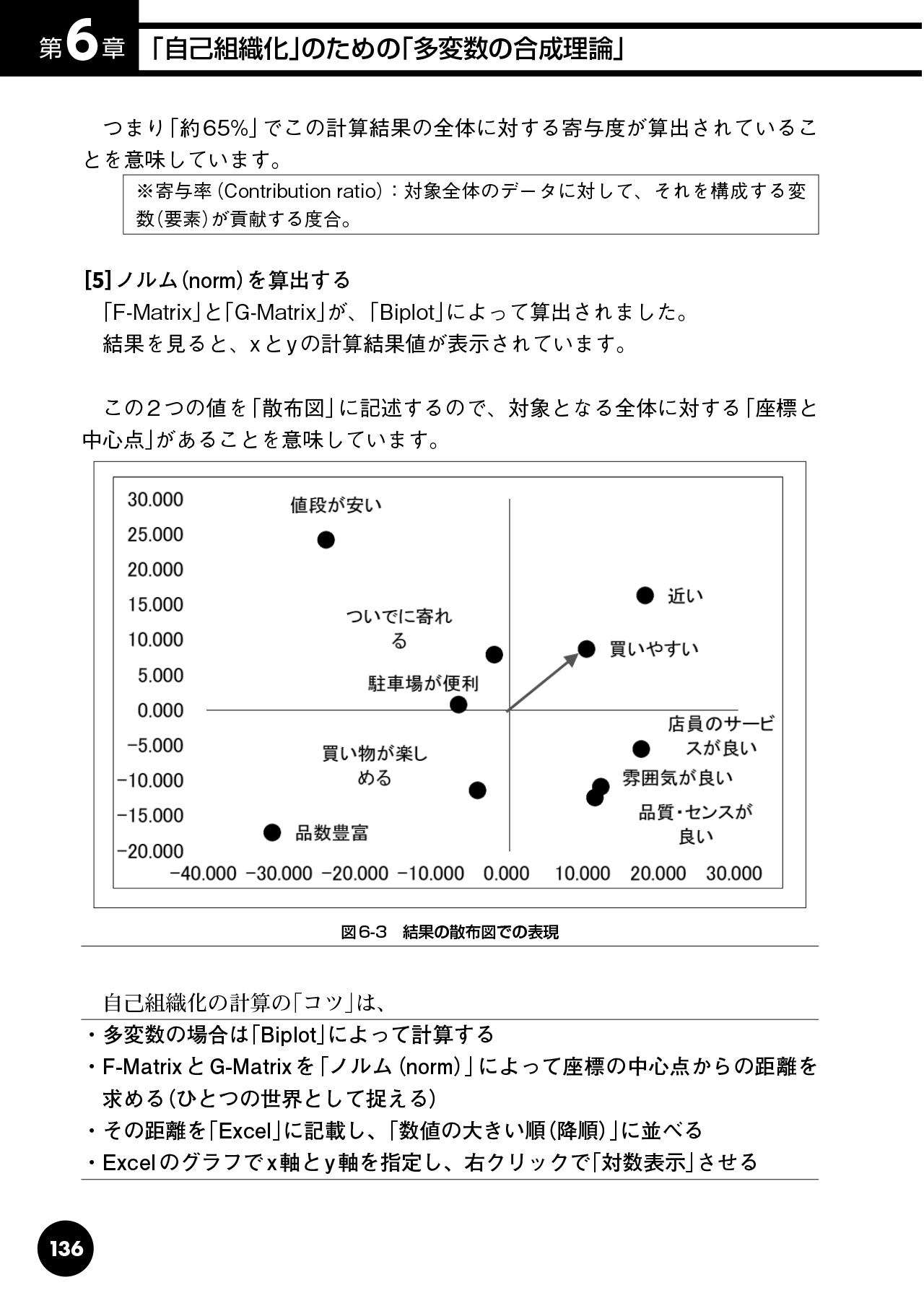
・時間に依存しない状態(Biplotの理論)
・固有値問題(固有値、固有ベクトル、固有値分解、特異値分解)
・時間に依存する状態(Kalman Filterの理論)
・群の臨界点を求める「自己相関関数」
|
本書内容に関するご質問は、こちら
本書のサポートページはこちら.
|
|
|