|
驚異の開発環境[GPU+CUDA]を使いこなす!

|
青木 尊之・額田 彰 共著
2009年11月19日発売
A5判
248ページ
定価 ¥2,530(本体 ¥2,300)
|
|
ISBN978-4-7775-1477-9 C3004 ¥2300E
|
 |
「CUDA」(クーダ)は、GPUをグラフィックス以外の演算処理でも利用できるようにするためにNVIDIAが提供する、統合開発環境です。C言語でプログラミングすることができ、FORTRANやC++といった他の言語もサポートされる予定です。
クロスプラットフォームで、「Windows」「Linux」「Mac OS X」などのOSと、「NVIDIA CUDA enable GPU」とを組み合わせて使います。
この「CUDA」を一躍有名にしたのが、東工大のスーパーコンピュータ「TSUBAME」(つばめ)でしょう。GPUによるアクセラレーションを用いた初のスーパーコンピュータとして、その名を世界に轟かせました。
著者の一人である青木尊之氏は、この「TSUBAME」でさまざまなアプリケーションを動かし、研究や開発に役立てている、東工大 学術国際情報センターの教授です。
本書は、第一線にいる著者が、「CUDA」を分かりやすく丁寧に解説した入門書です。
|
|
| ■ 主な内容 ■ |
|
本書刊行に寄せて
はじめに
| [2-1] 本書の目的 |
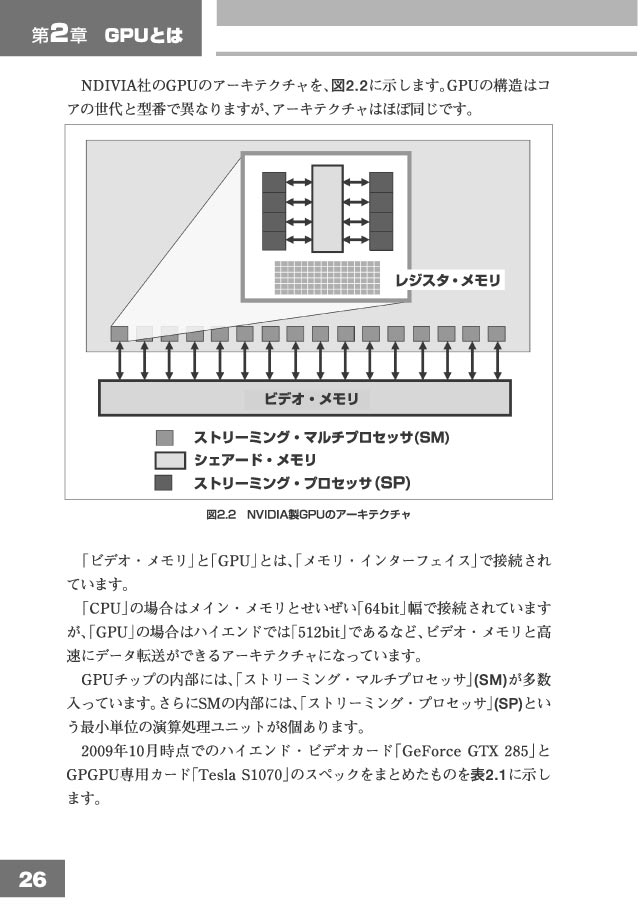
[2-2] GPUのアーキテクチャ |
| [2-3] GPUのバラエティ |
[2-4] 使っているGPUの情報の取得 |
| [3-1] CUDAプログラムを動かす仕組み |
[3-2] デバイス・メモリの確保 |
| [3-3] 「CPU→GPU」「GPU→CPU」のデータ転送 |
|
| [4-1] nvccコンパイラ |
[4-2] 4コンパイラ・オプション |
| [4-3] エミュレーション |
[4-4] エラー処理 |
| [5-1] スレッドの概念 |
[5-2] グリッドとブロック |
| [5-3] GPUカーネル関数 |
[5-4] ウォープ(Warp:縦糸) |
| [6-1] ハードウェアの観点から見たメモリの種類 |
[6-2] CUDAの階層的メモリ・モデル |
| [7-1] ビルトイン変数 |
[7-2] 修飾子(Qualifier) |
| [7-3] 同期をとる命令 |
[7-4] 数学関数 |
| [8-1] 1次元配列へのアクセス |
[8-2] 2次元配列へのアクセス |
| [8-3] メモリ・アクセスの最適化 |
[8-4] シェアード・メモリの「バンク・コンフリクト」(Bank Conflict) |
| [9-1] CUDA付属のライブラリ |
[9-2] ストリーム |
| [9-3] イベント |
[9-4] 「cudaSetDeviceFlags」関数 |
| [9-5] 「cudaHostAlloc」関数 |
[9-6] ドライバAPI |
| [9-7] プロファイラ |
|
| [11-1] 数値計算で常微分方程式を解く―「ルンゲ=クッタ法」 |
[11-2] 「粒子計算」に必要な「配列」の準備 |
| [11-3] 粒子の「初期条件」の計算 |
[11-4] 「粒子位置」の「時間積分」のプログラム |
| [11-5] 「CPUでの計算」と「GPUでの計算」のスイッチ |
[11-6] 「粒子位置」の「BMPファイル」への書き出し |
| [11-7] CPUとGPUの計算速度の比較 |
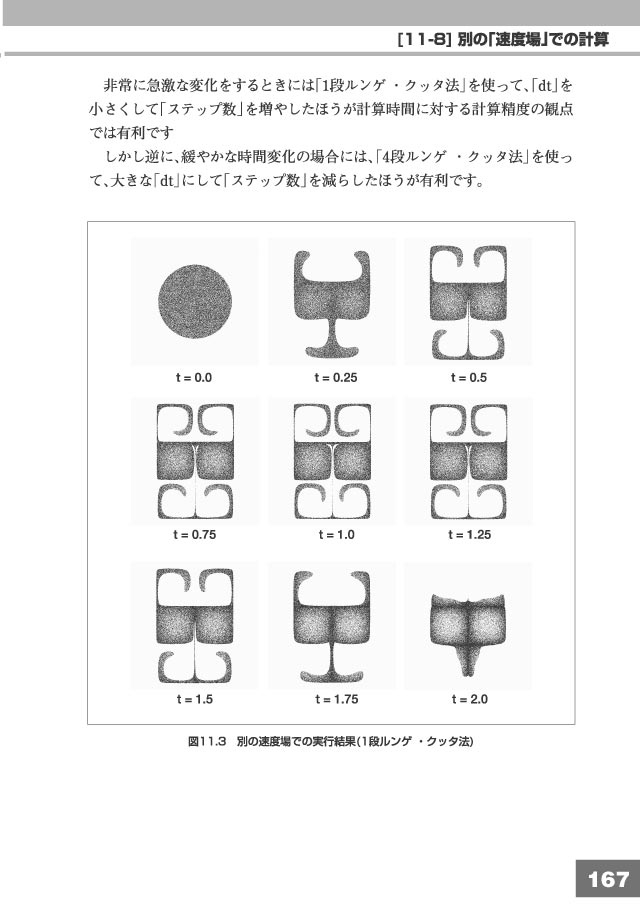
[11-8] 別の「速度場」での計算 |
| 第12章 |
「差分法」による「偏微分方程式」のGPU計算 |
| [12-1] 「拡散方程式」と「移流方程式」 |
[12-2] 「2次元拡散方程式」のGPUコンピューティング |
| [12-3] 「シェアード・メモリ」の利用 |
[12-4] 「シェアード・メモリ」の節約 |
| [12-5] 「変数」(レジスタ)の利用 |
|
| [A-1] Linux環境でのインストール |
[A-2] Windows環境でのインストール |
| [A-3] Mac OS X環境でのインストール |
|
| [B-1] CUDAのバージョンの変更履歴 |
[B-2] CUDA対応GPUの仕様 |
| GPUの取り付け |
コードネームFermi |
| Fermiの「ストリーミング・マルチプロセッサ」 |
Fermiの「グローバル・メモリアクセス」 |
| OpenCL |
東工大TSUBAMEのLINPACK |
| IONプラットフォーム |
姫野ベンチ(1) |
| 姫野ベンチ(2) |
|
サンプル・プログラムについて
索引
※ 内容が一部異なる場合があります。発売日は、東京の発売日であり、地域によっては1〜2日程度遅れることがあります。あらかじめご了承ください。
|
本書内容に関するご質問は、こちら
本書のサポートページはこちら.
|
|
|